Project Introduction | Path Planning of Robots in Intelligent Warehouse
This project is also part of my master's thesis, and it includes two aspects: global path planning of each robot and collaborative planning of multiple robots. My master's thesis (Written in Chinese) can be downloaded here.
Global Path Planning for Each Robot
Abstract:
To solve the routing problem in Mobile Robot Fulfillment System, firstly, a method based on traditional A* algorithm is proposed, and then a method based on improved A* algorithm considering task priority and utilization frequency of path nodes is further designed. Finally, a Markov decision process describing the problem is established, and a method based on Q-learning is proposed. Results of computational experiments show that these algorithms can quickly solve the problem. The methods based on the traditional A* algorithm and Q-learning can both obtain the shortest paths, and the method based on improved A* algorithm can effectively balance the traffic flow and significantly reduce the number of potential collisions.
Comparison between Traditional A* Algorithm and Improved A* Algorithm
Compared with the traditional A* algorithm, the improved A* algorithm takes into account the impact of factors such as task priority and path node heat when performing global path planning for each robot, thereby reasonably allocating traffic flow in the warehouse and reducing the difficulty of subsequent traffic control.
The comparison of path node heat caused by the above two global path planning algorithms is as follows. The darker the color, the more frequently the current cell is used.
- 5 AGVs, 20 tasks:
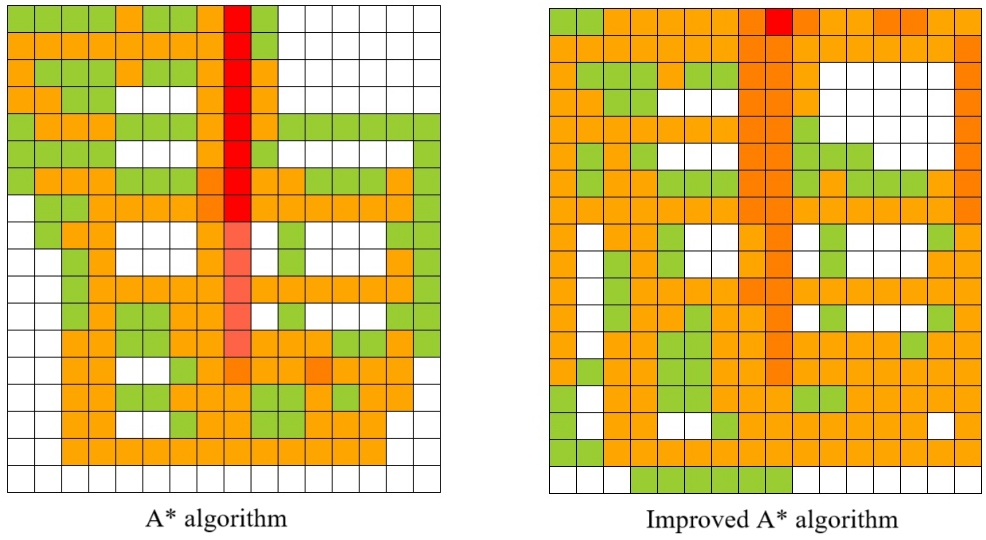
- 10 AGVs, 40 tasks:
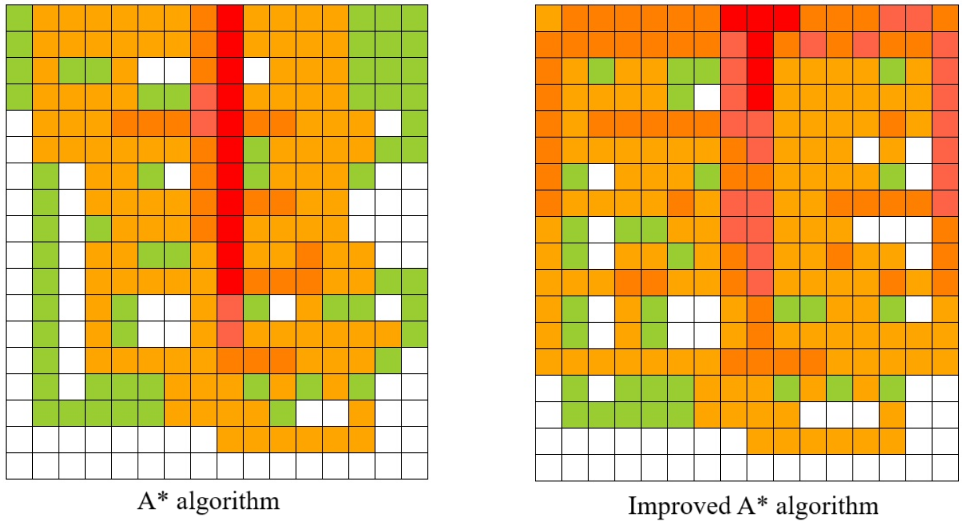
- 15 AGVs, 60 tasks:
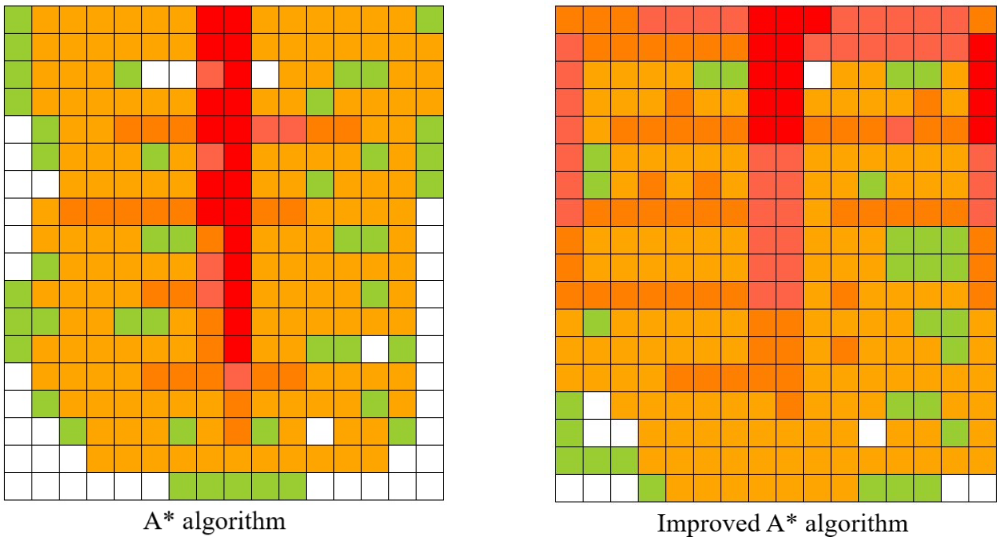
Q-learning Algorithm
The current state of the robot can be represented by the coordinates (x, y) of the cell it is in. Therefore, there are as many possible states of the robot as there are cells in the warehouse map. Each robot has only 4 actions to choose from: forward, backward, left, and right. Through training, the robot can take different actions in different states to achieve the exploration of warehouse path nodes.
Collaborative Planning of Multiple Robots
This part of work was also published in a Chinese journal. More details can be found in this paper. Here is a brief introduction to this part of work.
Abstract:
In order to solve the problem of multi-robot conflict-free motion planning in mobile robot warehousing systems, a Markov decision process model was established and a new solution method based on deep Q network (DQN) was proposed. The position of the robot was used as input information, and the DQN was used to estimate the maximum expected cumulative reward that can be obtained by taking each action in this state, and the classic deep Q learning algorithm was used for training. The calculation results of the example show that this method can effectively overcome the collision problem of multiple robots in motion, enabling the robots to complete the shelf handling task without conflict.
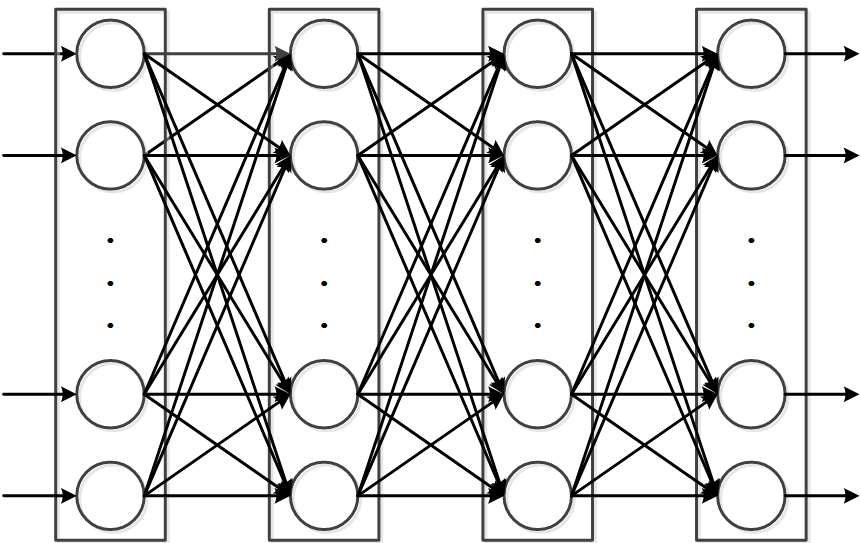
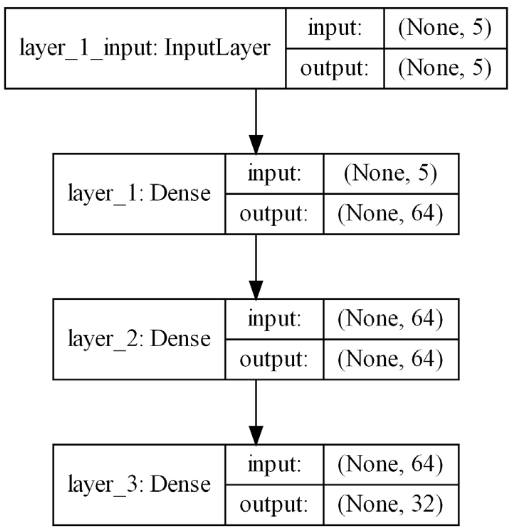
Neural Network Architecture
Both the online network and the target network consist of a 3-layer fully connected network, including 1 input layer, 2 hidden layers and 1 output layer, as shown in the following figure:
Experience Reuse Mechanism
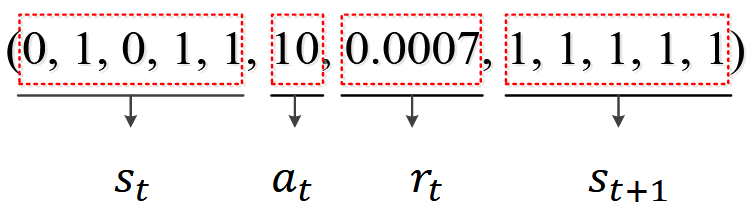
The experience gained by the agent in each step of interaction with the environment is stored in the experience reuse pool, and some experience is randomly extracted from it for learning during each training. Taking 5 robots as an example, the composition of an experience sequence is as follows:
Training Details
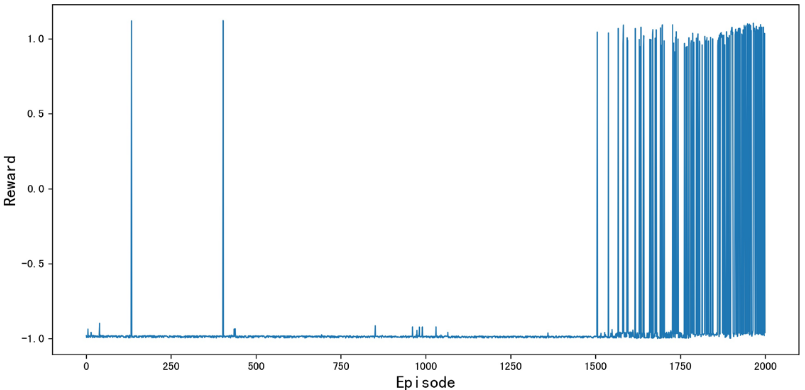
An example of reward changes during training is as follows:
Simulation Animation
This part of the animation demonstration is based on Python's OpenCV library.